Idunno: Distributed Inferencer
This project implements a distributed inferencer that is fault-tolerant and scalable. It offers group membership, distributed storage, and job scheduling.
Fault tolerant: Allow up to 30% simutaneous node failures before system converges
Scalable: (not tested with scaling, but theoretically scalable)
This project borrows some ideas from RAY Project. The ambition was to learn and a vanilla RAY, but the reality…
Client usage
Run the client with: python3 idunno.py client
Then start inference:
1
2
3
train model_name # no magic here, just some APIs
upload input_directory [file_cnt]
inference model_name data_dir
System Model
- Fail-stop
- Failure: 30% failure before converges
- Resources: same (compute) resources for all workers
- Has a simple & reliable core
(one ring to rule them all) - more to come…
System Overview
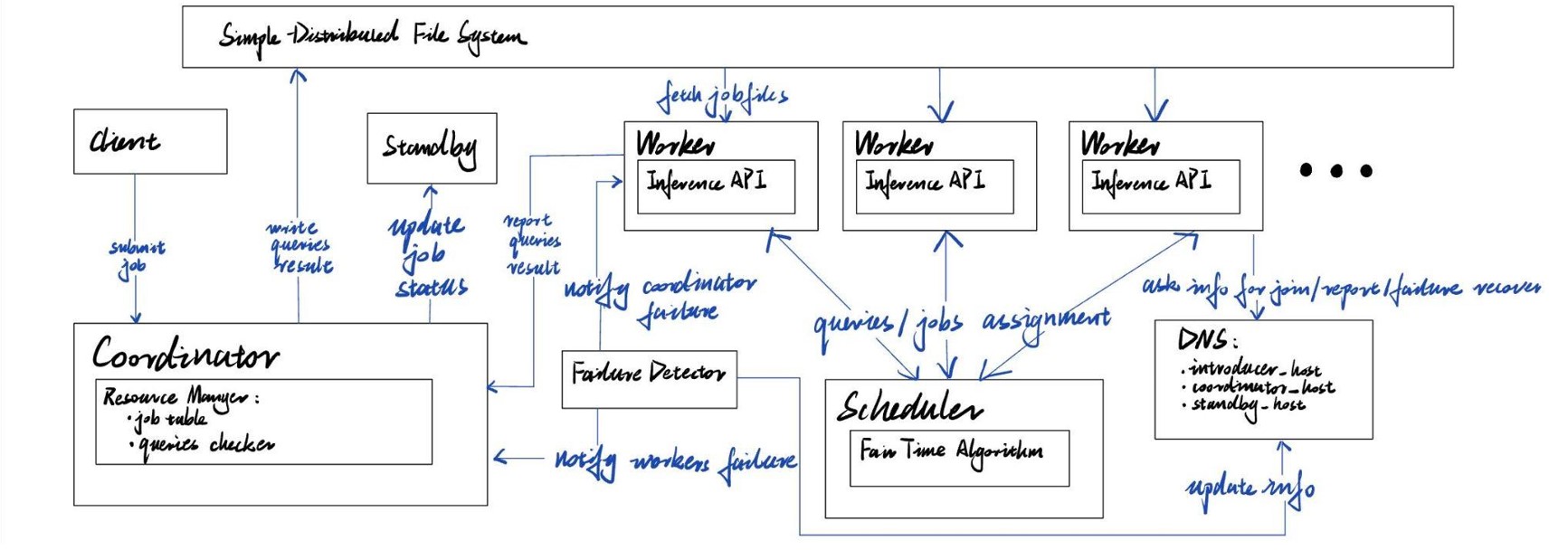
Each node is either a coordinator or worker. Table bellow summarizes their differences:
| Coordinator | Worker | |
|---|---|---|
| Communicate with | client, worker | coordinator |
| Membership | Yes | Yes |
| Scheduling | Master | worker |
| Replica | r = 2 | no replica |
When a client submits a job:
- Coordinator segments job to fit each worker’s capacity
- Coordinator decides allocation of resources to each job
- Each worker asks for job, executes the job, report to coordinator when completed, ask again
On worker failure/leaving:
- Coordinator detects worker failure through membership service
- Jobs in failed workers are available for other workers to work on
On coordinator failure:
- Workers detects coordinator failure through membership service
- Asks the reliable core for another coordinator address
On worker rejoins:
- Nothing changes for inferencer, the new worker simply asks for jobs
- Group membership and file system updated
Distributed File System
Group Membership Service
Job Scheduler
This post is licensed under CC BY 4.0 by the author.